AEO for Ecommerce: Get Products Recommended by AI
Ecommerce AEO requires a different playbook. Learn how Product schema, buyer reviews, and comparison sites get your products cited by AI assistants.
On this page

A year ago, the path to a wireless-earbuds purchase started in Amazon search. In 2026 it starts in a chat box. A shopper opens ChatGPT and asks "what's the best wireless earbuds under $100 for running?" Before they ever type "amazon" or "best buy", they get three picks, a short comparison, and a Shopping card with two of them linked. If your SKU isn't in that synthesis, you lost the click.
This is the new top of the funnel for retail. ChatGPT now returns Shopping cards in commercial answers, fed by Bing's product index. Gemini's AI Overviews surfaces products in cards on Google for shopping queries. Perplexity does price-and-features comparison inline and links straight to the retailer. Sonos, Bose, Allbirds, Yeti — every brand we scan that wins consumer-product queries shows up in those answers consistently. Every brand that doesn't, isn't there. The category-defining names are in the synthesis; the rest are absent.
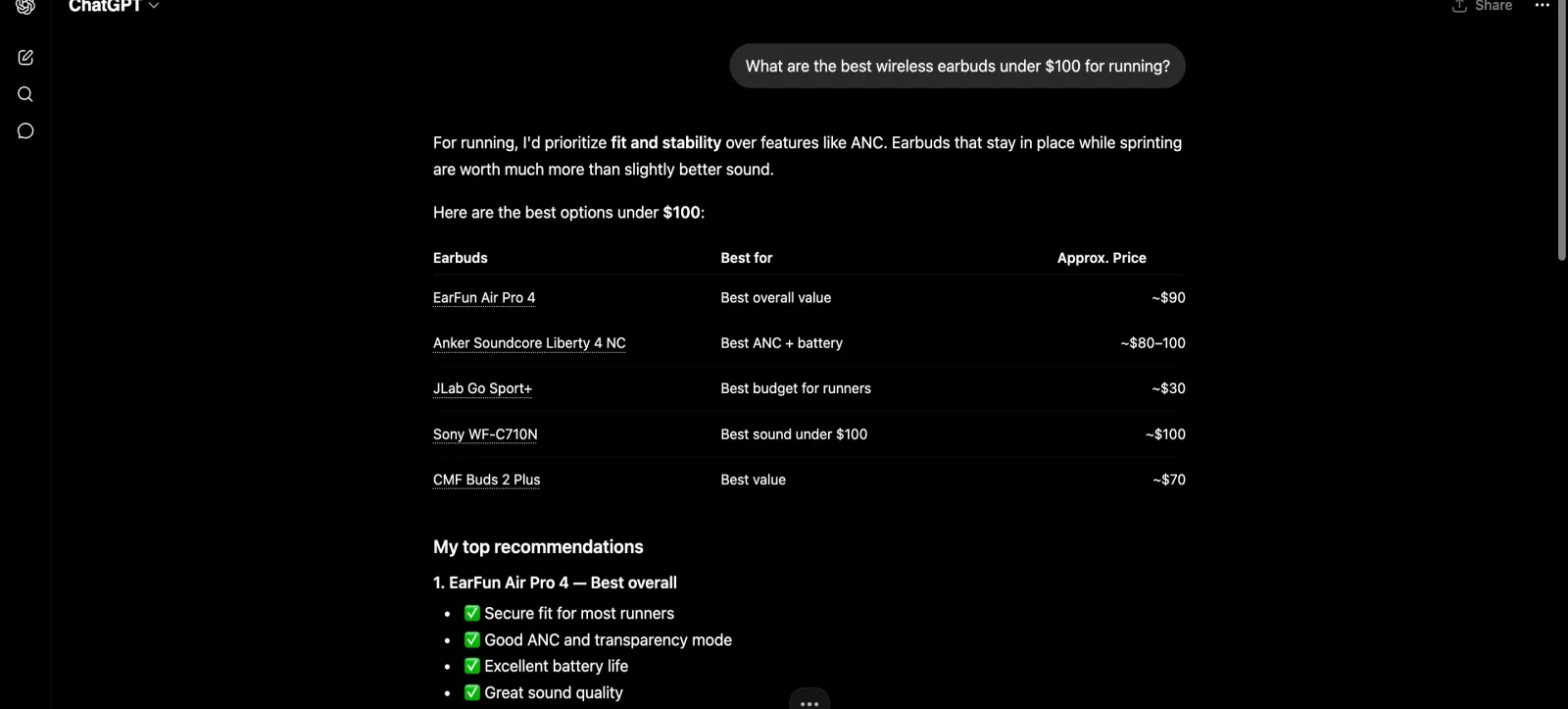
Example: a real ChatGPT answer to a buyer query — it names EarFun, Anker, JLab and Sony and ranks them. This is the shortlist your brand needs to be on.
The catch: the playbook that gets a SaaS or B2B brand cited is not the playbook that gets an ecommerce brand cited. Reviews matter differently. Schema matters more. The publications that move the needle are completely different. Ecommerce AEO is a different sport, and most retail marketing teams are running the generic playbook. This is the catalog-specific version.
Curious how your site does?
Run this same scan on your site — free, about 60 seconds, no signup.
How AI engines treat ecommerce differently
Three architectural facts shape every ecommerce citation we see in our scans:
The engines over-index on Product schema + verified review markup. For an article or guide, JSON-LD is a nice-to-have. For a product page, it's the difference between being citable and being invisible. The retrieval pass scores product pages partly on whether Product + Offer + AggregateRating resolve cleanly. We've seen pages with thin copy and rich schema outrank pages with detailed copy and no schema, every time. It's the most underused signal in retail.
Editorial review sites dominate citations more than brand pages do. Wirecutter, RTINGS, Consumer Reports, The Strategist — and category-specific reviewers like Pitchfork for music gear, Outdoor Gear Lab for camping, Wirecutter (again) for kitchen — get cited 3–4× as often as the brand's own product page on most "best X for Y" queries. ChatGPT will quote Wirecutter's pick of the Bose QuietComfort Ultra before it quotes anything Bose published themselves. The brand is the recommendation; the third party is the source.
Each engine pulls from a different product index. ChatGPT's Shopping cards come from Bing Shopping. Gemini's AI Overviews pull from Google Shopping. Perplexity has built its own product index and licenses some retailer feeds. Different distribution pipes means different optimization work — getting into one doesn't get you into the others. If you've already read our Perplexity citations playbook and our breakdown of how to get cited by Gemini, file this post as the catalog-side companion. The general patterns still apply; the ecommerce-specific ones go further.
The 5 signals that matter for ecommerce AEO
We've audited hundreds of retail catalogs across our scans. Five signals separate the SKUs that get cited from the ones that don't:
1. Product schema with all five required properties
A Product JSON-LD block with just name and description is half a signal. The block that wins citations has all five:
offers— withprice,priceCurrency,availability,priceValidUntilaggregateRating—ratingValueandreviewCountreview— at least 3 individual reviews withauthor,reviewRating,reviewBodyavailability—InStock/OutOfStock(Perplexity demotes out-of-stock SKUs hard)brand— as a nestedBrandentity, not a string
Most catalogs we audit have two of these. The ones with all five get pulled into context at a much higher rate. You can emit the right shape in 30 seconds with our schema generator — and our AEO audit tool flags missing properties on any URL you paste in.
2. Verified review markup (not bot reviews)
The engines have learned to detect fake reviews. A product with 4,000 5-star reviews posted in a 6-week window signals fraud — Perplexity and ChatGPT now visibly down-weight catalogs where this pattern shows up. The signal that wins is verified review markup: Trustpilot Verified, Bazaarvoice Authenticated, Yotpo with an isVerified flag in the JSON-LD. A product with 200 verified reviews ranks higher in the citation pass than the same product with 4,000 unverified ones. We've watched competitors with smaller catalogs but cleaner review programs eat citation share from larger brands.
3. Earned citations from category-defining review sites
For tech: Wirecutter, RTINGS, Tom's Guide. For style: The Strategist, GQ, Vogue. For outdoor: Outdoor Gear Lab, Backpacker, Switchback Travel. For kitchen: America's Test Kitchen, Wirecutter. For music gear: Pitchfork, Sweetwater editorial. One placement in a Wirecutter roundup is worth roughly six months of consistent citation across every AI engine we track. Allbirds, Casper, Warby Parker — the D2C brands that won early didn't win on owned content. They won by getting into The Strategist and The New York Times' product roundups.
4. Image quality and descriptive alt text
Gemini and Claude both read product images. We've watched ChatGPT (which can also do visual analysis when invoked) pull product details directly from images when the page copy was thin, and the same multi-modal behavior shows up in how to get cited by Claude. Multi-modal engines genuinely look at the JPEG. The bare-minimum signal: descriptive alt text on every product image. Not "Sonos Move 2 image 1" but "Sonos Move 2 portable speaker in shadow black, side angle, with mesh grille and capacitive touch controls visible." The descriptive version gets cited; the generic version doesn't.
5. Price freshness and structured availability
Perplexity in particular re-crawls product pages on the order of days, not weeks, on hot commercial queries. A stale price in your offers block — last week's price showing as current — gets the page demoted at the re-rank stage. Worse, an out-of-stock SKU with no availability: OutOfStock flag signals data quality issues. Keep your structured availability live. If your CMS doesn't auto-update the JSON-LD when your inventory does, that's the highest-leverage bug to fix in your catalog.
The 6 tactics that move ecommerce AEO citations
Ranked by leverage per hour invested, not by how loud the AEO industry is about them:
Tactic 1 — Ship full Product schema with all 5 required props
Twenty minutes per template, six months of payoff. Audit your product page template (you probably have one or two — Shopify section, custom React component, whatever). Confirm offers, aggregateRating, review, availability, and brand all populate dynamically. Run the page through Google's Rich Results Test to confirm validity. Then run it through our schema generator to compare against a clean reference. The gap is almost always larger than teams expect — we routinely find catalogs where aggregateRating is hardcoded to 4.5 instead of pulling from the actual review database.
Tactic 2 — Earn placement in a Wirecutter / RTINGS / Strategist roundup
The highest-leverage AEO move for any ecommerce brand. One mention in "The 5 best wireless earbuds for running" on Wirecutter shows up in ChatGPT, Claude, Copilot, Perplexity, and Gemini answers for variants of that query for six months. The PR motion: pitch the relevant editor with the product and the angle they care about (durability, price-to-performance, niche use case), not your generic launch announcement. Patagonia and Yeti both built early AEO presence almost entirely on earned editorial — neither runs much paid affiliate content for premium SKUs.
Tactic 3 — Build comparison pages on your own domain
"Sonos vs Bose vs Beats: which is best for outdoor use" — published on yourdomain.com, with all three products honestly compared (yes, including when a competitor wins on a dimension) — wins the synthesis layer at a rate the brand's own product page cannot. The engines treat comparison pages as more citation-worthy than promotional pages. Casper's mattress comparison content was a major reason it dominated AI mattress citations for two years. The trick is honesty: a comparison that always concludes "and that's why ours is best" gets sniffed out and down-ranked. A comparison where you genuinely concede some dimensions to a competitor gets cited.
Tactic 4 — Verified review programs (not fake review programs)
Trustpilot Verified, Bazaarvoice Authenticated, Google Customer Reviews — these signals carry weight precisely because they're hard to fake. A program that asks every actual buyer for a review (post-fulfillment email, accept the negative ones, respond publicly to complaints) builds a verified review base that engines read as authentic. Our scans consistently show that brands with mid-volume verified reviews outperform brands with high-volume unverified reviews on citation share.
Tactic 5 — Submit feeds to Google Shopping + Bing Shopping
The ChatGPT pipe runs through Bing. The Gemini pipe runs through Google. Both require well-formed product feeds in Google Merchant Center and Microsoft Merchant Center respectively. Most retailers we audit have the Google feed live and the Bing feed neglected — that's a direct ChatGPT visibility hole. Match the two feeds, keep them synced with inventory, and confirm GTIN and brand identifiers resolve cleanly.
Tactic 6 — Measure citation rates per-SKU, not just per-brand
This is the move most ecommerce teams skip. Brand-level visibility ("Sonos is mentioned in 67% of category answers") obscures the SKU-level reality ("the Sonos Move 2 is cited at 85%, the Roam at 41%, the Era 100 barely shows up"). Run our AI visibility checker at the SKU level — pick your top 20 products and track each individually, then tie the deltas back to revenue with how to measure AEO ROI. The patterns are usually clear: the products with editorial roundup placement crush the ones without, even inside the same brand. That tells you where to direct the next PR budget.
What NOT to do (the ecommerce-specific traps)
Three anti-patterns we see crater retail catalog visibility:
- Fake reviews on Trustpilot, Amazon, or your own site. The platforms detect these and filter them, and the engines cross-reference. A catalog with detected fake reviews gets a punishing visibility hit across all nine engines — not just on the affected SKUs but on the brand entity. Warby Parker famously avoided this trap and built genuine review depth instead. The ROI difference shows up in citation share to this day.
- Skipping image alt text. Multi-modal engines read your images. Generic alt text ("product photo 1") trains the embedding to treat your image as low-quality content. Descriptive alt text turns the image into an additional ranking signal. The CMS-default behavior is wrong here for almost every brand — audit yours.
- Assuming SEO-rich pages auto-translate to AEO. A product page that's optimized for keyword density and long-tail SEO patterns ("best running shoes for flat feet plantar fasciitis 2026") often loses to a cleaner page that answers the specific question with structured data. Citation extraction is a different mechanism than rank — the page that wins position 3 in Google might not be the page that wins citation in ChatGPT (more on that split in AEO vs SEO). Stop assuming the work is the same.
How to verify your work
The closed-loop check is straightforward: query each engine for the prompts that matter to your category — "best [product] for [use case]", "[product A] vs [product B]", "[product] under $[price]" — and check whether your SKUs appear, who else does, and which citation sources keep showing up. Wirecutter on every answer? You need to be in Wirecutter. Amazon listings winning? Your DTC schema is probably weaker than the Amazon listing's.
Do this manually for a week to build intuition — open ChatGPT, Perplexity, Gemini in three browser tabs and run the same 20 prompts. Note the citation sources. The patterns will be obvious by Friday.
After that, automate. Our AI visibility checker runs the queries on a schedule across all nine engines (ChatGPT, Claude, Copilot, Gemini, Perplexity, Grok, DeepSeek, Google AI Overviews, Google AI Mode), parses citations, rolls up per-SKU and per-brand visibility, and surfaces the citation-source patterns we've described above. Re-scan weekly after each catalog change — the deltas tell you which tactics moved the rate and which didn't. The full AEO tools catalog covers the other pieces (schema generation, llms.txt, citation-source radar) you'll want once you have a measurement baseline.
TL;DR
Ecommerce AEO is its own discipline. Product schema with all five required properties is the highest-leverage technical signal in any catalog. Verified review markup beats unverified review volume. Earned editorial placement on Wirecutter, RTINGS, The Strategist, and category-specific reviewers compounds harder than any owned content investment. Build honest comparison pages on your domain. Submit feeds to both Bing Shopping (ChatGPT pipe) and Google Shopping (Gemini pipe). Measure citation rates per-SKU, not just per-brand. Avoid fake reviews, skipped image alt text, and the assumption that SEO-rich pages auto-translate. The brands winning AI shopping queries in 2026 — Sonos, Bose, Yeti, Allbirds — got there on these signals, not on bigger content libraries.
FAQ
Why is ecommerce AEO a different sport from SaaS or B2B AEO?
The playbook that gets a SaaS or B2B brand cited is not the same one that gets an ecommerce brand cited. Reviews matter differently, schema matters more, and the publications that move the needle are completely different.
What Product schema properties do I need to get cited by AI?
The winning Product JSON-LD block has all five: offers (with price, priceCurrency, availability, priceValidUntil), aggregateRating, at least three individual review entries, availability (InStock/OutOfStock), and brand as a nested entity rather than a string. Most catalogs only have two of these.
Do verified reviews really beat a higher volume of unverified reviews?
Yes. A product with 200 verified reviews ranks higher in the citation pass than the same product with 4,000 unverified ones, because engines now detect and down-weight fake review patterns. Verified markup like Trustpilot Verified, Bazaarvoice Authenticated, or Yotpo with an isVerified flag carries weight precisely because it is hard to fake.
Why do editorial review sites get cited more than my own product pages?
Sites like Wirecutter, RTINGS, Consumer Reports, and The Strategist get cited 3–4× as often as a brand's own product page on most "best X for Y" queries. The brand is the recommendation, but the third party is the source AI engines quote.
Why should I measure AI citation rates per-SKU instead of per-brand?
Brand-level visibility obscures the SKU-level reality — one product can be cited at 85% while another barely shows up. Tracking your top products individually reveals that SKUs with editorial roundup placement crush those without, even inside the same brand, which tells you where to direct PR budget.
Related reading
AEO for SaaS: Get Recommended by AI Assistants
AEO for SaaS companies: why G2 reviews outweigh content, how comparison pages win, and the playbook to get your product into AI answers.
13 min readAEO for B2B: Get Found in AI Answers
B2B buyers ask long, specific questions in AI engines before sales talks begin. Here is the B2B AEO playbook for earning citations and brand mentions.
13 min readAEO for Local Business: Get Found in AI Search
Local AEO differs from generic AEO. Learn how to get your business recommended by Gemini, ChatGPT, Copilot, and AI Overviews for near-me queries.
12 min readHow to get cited by Perplexity: a 2026 playbook
Perplexity cites 4-8 sources per answer and the patterns are learnable. Here are the 8 we see in cited content, with copy-paste tactics.
10 min readHow to Get Cited by Gemini in 2026
How to get cited by Gemini: it runs on classic SEO plus AI-specific signals. Learn the 2026 playbook for rankings in AI Overviews and Gemini answers.
12 min readWhy ChatGPT doesn't recommend your brand
ChatGPT SEO fix: six reasons ChatGPT names competitors instead of you, ranked by frequency across 1,000+ FixAEO scans — with a fix for each.
8 min read
Free AEO tools
Put this into practice with free FixAEO tools — no signup required.
AI Visibility Checker
Score your brand across 9 AI engines
AEO Audit Tool
Answer-engine readiness scan
Schema Generator
Build valid JSON-LD structured data
llms.txt Generator
Create a spec-compliant llms.txt
Sitemap Validator
Check your XML sitemap for errors
AI Content Grader
Grade content for AI citation readiness
See how your own site scores
FixAEO runs every check in this post automatically. Free, no signup.