The 30-point AEO audit checklist (2026)
AEO audit checklist: 30 signals across 7 categories — from crawler access to per-engine verification. Copy it into Notion and run your audit today.
On this page

Last updated: 2026-05-31. This checklist is maintained quarterly — AI engines change fast, third-party signals decay, and structured-data conventions drift.
Most "SEO audit" templates floating around in 2026 still don't include a single AEO-specific signal. They check title tags, meta descriptions, page speed, schema basics, and call it a day. None of them ask whether ChatGPT can reach your domain, whether your Wikidata entity is linked from sameAs, whether your llms.txt is spec-compliant, or whether buyers asking AI assistants for your category ever hear your brand name. That's the gap this checklist fills.
This is the AEO checklist we use internally on every FixAEO scan — 30 signals across 7 categories, written in the order we audit them. It's designed to be copy-pasted into Notion, Google Docs, Linear, or whatever your team uses, and worked through over a focused afternoon. If you want the automated version, our AEO audit tool runs every check below in 30 seconds. If you want to learn the craft, work through it manually first. Both paths land in the same place.
Jump to: Crawler access · Structured data · Content structure · Entity signals · Third-party signals · Per-engine checks · Measurement · Fastest items first
Curious how your site does?
Run this same scan on your site — free, about 60 seconds, no signup.
At a glance
| # | Category | Items | Est. time |
|---|---|---|---|
| 1 | Crawler access | 4 | 30-45 min |
| 2 | Structured data | 5 | 60-90 min |
| 3 | Content structure | 5 | 60-120 min |
| 4 | Entity signals | 4 | 90-180 min |
| 5 | Third-party signals | 4 | ongoing |
| 6 | Per-engine checks | 6 | ~60 min |
| 7 | Measurement | 2 | ~30 min |
| Total | 30 | 5-9 hrs |
How to use this checklist
Work through it top to bottom. Each item takes 5 to 30 minutes the first time. A thorough first-pass audit runs 3 to 5 hours end to end. Re-run quarterly — AI engines change fast, third-party signals decay, and structured data drifts as engineering ships new templates. Keep the list itself version-controlled somewhere your team owns. The fastest way to lose AEO ground is to do this once, declare victory, and never come back.
The links beside each item point at the FixAEO tool that runs that specific check automatically. You can audit fully by hand — the checklist works either way.
Category 1 — Crawler access (4 items)
This is the foundation. If AI crawlers can't fetch your pages, none of the rest matters. We see roughly one in three sites we scan blocking at least one major AI bot in robots.txt without realizing it.
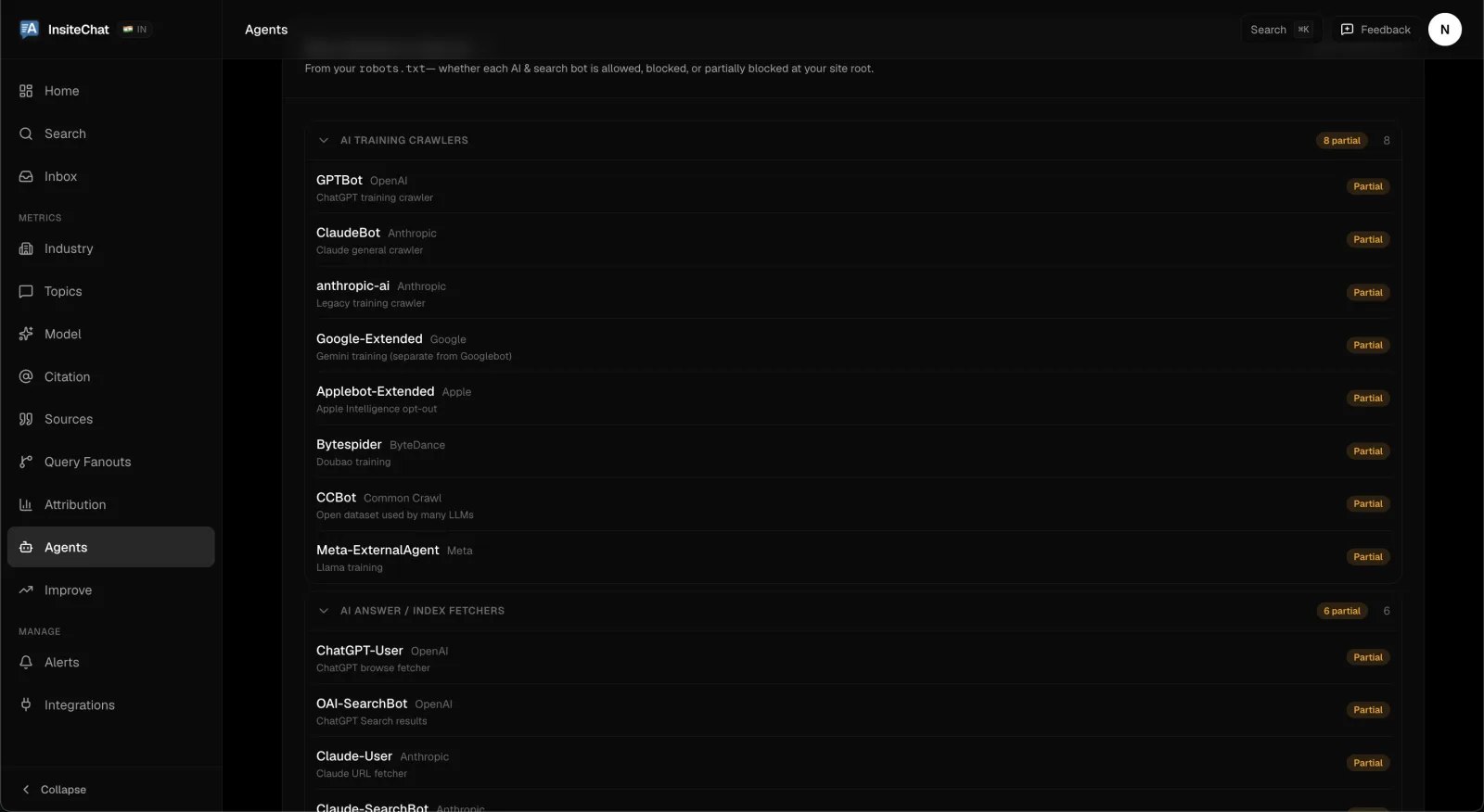
Example: per-bot crawl access (GPTBot, ClaudeBot, Google-Extended…) for InsiteChat — FixAEO.
-
robots.txtdoesn't block AI crawlers — confirmGPTBot,ClaudeBot,anthropic-ai1,Google-Extended,PerplexityBot,CCBot, andBytespiderare not underDisallow: /. Many CMS defaults block CCBot or Google-Extended without telling you. Audit with our robots.txt checker. For a clean reference, look at how Stripe's robots.txt is structured at https://stripe.com/robots.txt — explicit allows beat silent defaults. -
/llms.txtexists and is spec-compliant — the file should live at your root, follow the llmstxt.org spec2, and curate your highest-value pages (docs root, top product pages, key blog posts, changelog). Most sites in 2026 still don't have one. Generate one in under a minute with our llms-txt generator. -
/sitemap.xmlexists and validates — every important page is reachable from it, lastmod dates are recent, and the file passes XML validation. AI crawlers don't strictly require sitemaps but the ones that read them prefer them. Run our sitemap validator. - Canonical tags are clean — no duplicate canonicals, no canonical chains, no self-conflicting tags. AI crawlers de-dupe aggressively and the wrong canonical hides the right page. Audit with our canonical tag checker.
Category 2 — Structured data (5 items)
Schema is how you tell AI engines what your pages mean in a machine-readable format. We've watched citation rates jump 15-25% within a month for sites that go from no schema to a clean stack.
- Organization JSON-LD on homepage — must include
name,url,logo,description, and asameAsarray pointing to LinkedIn, X, Crunchbase, your Wikipedia page (if you have one), and your Wikidata QID. Generate it with our schema generator. - Article schema on every blog post3 —
headline,datePublished,dateModified,author(as aPersonwith their own URL),mainEntityOfPage, andimage. Claude and Perplexity both reach for this when answering "who said X" queries. Build it with our schema generator. - FAQPage schema on every FAQ section —
Question.namemust be the actual user question,Answer.textmust be a complete 40-80 word answer. Perplexity over-indexes on this format. Spin it up with our schema generator. - Product or SoftwareApplication schema on product pages —
SoftwareApplicationfor SaaS (withapplicationCategory,operatingSystem,offers,aggregateRating);Productfor ecommerce (withoffers,aggregateRating,review,brand). One or the other, not generic. Generate either with our schema generator. - BreadcrumbList on every inner page — a 3-4 item breadcrumb gives AI engines hierarchical context. Most CMS exports skip this entirely. Add it via our schema generator. Bonus: if you run a brick-and-mortar storefront, also run a Google Business Profile audit and ship LocalBusiness schema to match.
Category 3 — Content structure (5 items)
The retrieval pass scores content chunks against the user's query. Question-form H1s and direct answers in the first 200 words score higher than marketing prose every time.
- Top 10 pages have question-form H1s — not "Best CRM Software Platform 2026" but "What's the best CRM for a 10-person SaaS startup?" Conversational, specific, matches how buyers query AI engines. Audit your top traffic pages by Google Search Console and rewrite the bottom half.
- Direct answer in first 200 words of each page — the question stated, then answered. AI engines pull the first chunk as context heavily, so burying the answer below product marketing copy loses citations. Look at how Notion's help docs are structured for the pattern — answer first, context second.
- Numbers, lists, tables in body — citation-friendly formats. AI engines pull lists and tables into responses verbatim. Pages that lean prose get summarized; pages with structured comparisons get quoted. At least 1 table or numbered list per 1000 words is a reasonable floor.
- "Last updated: [date]" visible on the page — not just in metadata. Perplexity and Gemini both implicitly down-rank stale content, and a visible
lastUpdatedfield with a recent date is the cheapest freshness signal you can ship. We update our highest-traffic posts quarterly and the citation rate lifts each time. - At least 5 internal links per page — no orphans. AI crawlers follow your internal graph the way Google does. Pages with zero inbound internal links get retrieved less often, and pages with zero outbound links get retrieved without supporting context. We aim for 5-15 contextual internal links per page minimum.
Category 4 — Entity signals (4 items)
This is the layer most marketing teams undervalue. AI engines disambiguate brands at retrieval time using entity graphs, and the brands with strong entity presence get cited even when the user query doesn't name them.
- Wikidata QID exists and is
sameAs-linked from Organization schema — go to wikidata.org and either find or create your entity (free, lightweight, way easier than getting a Wikipedia page approved). Once your QID is live, link to it from your Organization JSON-LDsameAs. This is one of the highest-leverage AEO investments any brand can make for under an hour of work. - Wikipedia entry, if notable enough4 — Series A SaaS, listed ecommerce brands, multi-location local businesses, and most B2B brands with industry coverage clear the notability bar. Wikipedia gets ~5-10× the per-token weight of typical web crawl during foundation-model training. If you qualify, prioritize it.
- LinkedIn Company Page is consistent — same brand name, same URL, same logo, same one-line description as the rest of your web presence. Mismatches are a disambiguation signal AI engines penalize. Stripe, Notion, and Linear all keep these in tight sync; teams who let LinkedIn drift lose citations.
- Crunchbase entry has correct funding, team, and product data — Crunchbase feeds a surprising amount of AI training data on company entities. An outdated Crunchbase entry with the wrong funding stage or stale leadership is a quiet citation drag for B2B brands.
Category 5 — Third-party signals (4 items)
AI engines treat third-party validation as orthogonal trust signals. They are not optional for commercial queries.
- 30+ recent verified reviews on the right platform for your category — G2 + Capterra for SaaS, Yelp + Google Business Profile for local, Trustpilot + Amazon for ecommerce, Glassdoor + LinkedIn for employer-brand queries. The threshold that moves Claude citations measurably is 50+ with at least 10 added in the last 90 days. Below 30, you're in the noise floor.
- At least 1 mid-tier publication citation in the last 12 months — TechCrunch, The Verge, The Information, Ars Technica, plus deep-niche trades (Marketing Brew, The Pragmatic Engineer, Restaurant Dive, etc.). One real feature beats twenty self-published posts for Claude and Perplexity.
- Mentioned in at least 1 "best of" or comparison roundup — the third-party "best CRM for startups" or "best running shoes 2026" pages are exactly the surfaces AI engines retrieve from for buyer-intent queries. Earn placement in those roundups, by pitching the publication or by being good enough that they find you.
- Citations from authoritative source domains in your niche — track which sources AI engines pull from when answering your category queries. Some surprise you. Track them with our AI citation source radar — it surfaces the third-party domains feeding citations for your category so you can pursue placement deliberately.
Category 6 — Per-engine checks (6 items)
Each engine rewards different signals. Don't run one generic playbook across all nine — you'll leave citation share on the table at every one. Check each engine individually.
- ChatGPT: domain returns a sensible response for "best [your category]" queries — open ChatGPT in a private window, ask the question your buyer asks, and read whether your brand appears. If not, see why ChatGPT doesn't recommend your brand for the diagnostic path.
- Claude: third-party validation graph is strong — Claude weights authoritative third-party sources heavily. If your G2, Wikipedia, and mid-tier press footprint is thin, Claude underperforms. Work through how to get cited by Claude for the Claude-specific playbook.
- Gemini: top 10 Google rank for primary query + Knowledge Panel — Gemini still leans on Google's index more than other engines. If you're invisible on Google for your category, you're invisible on Gemini too. The fix path is in how to get cited by Gemini.
- Perplexity: cited in at least 1 buyer-intent prompt — Perplexity exposes its sources transparently. Test 5 prompts in your category and read the citation panel. The Perplexity citations playbook walks through the FAQPage + freshness pattern that moves Perplexity specifically.
- Grok: active X/Twitter presence with recent engagement — Grok over-indexes on X content because xAI trains it on X data. A dormant X account is a Grok citation drag. The full pattern is in how to get cited by Grok.
- DeepSeek: Chinese-language footprint or strong technical/dev signals — DeepSeek over-indexes on documentation in code repos and Chinese-market content. If you're a dev tool, your GitHub README is half the battle. The engine-specific path is in how to get cited by DeepSeek.
Category 7 — Measurement (2 items)
Citation work without measurement is a vibe. These two items close the loop.
- 20+ tracked prompts defined — the questions your buyers ask AI engines, written conversationally and ICP-specific. Not "best CRM" but "best CRM for a 10-person SaaS team with a $30k/yr software budget." Twenty prompts is the floor; 50 is better. The full set lives in our prompt-tracking surface inside the AEO audit tool, or use copy-paste Claude prompts to run your audit if you want to do this step by hand.
- Visibility scanning runs weekly across all 9 engines — daily during active campaigns, weekly otherwise. Manual checks drift fast and miss the deltas that matter. Run the loop through our AI visibility checker — it queries Claude, Copilot, ChatGPT, Gemini, Perplexity, Grok, DeepSeek, Google AI Overviews, and Google AI Mode for your tracked prompts and scores citation rates, sentiment, and share of voice against named competitors.
What an "all-checked" AEO score looks like
Most teams running this AEO audit checklist for the first time check 8 to 12 of the 30 items. After a focused quarter, 20 to 25. All 30 checked is rare and sits in competitive-moat territory — Stripe, Notion, and Linear are roughly there for their categories; the median Series B SaaS is closer to 18; pre-seed brands typically check 5 to 8.
The point of the checklist isn't to score 30 immediately. It's to know which items you've moved past, which are next, and where your competitors actually sit. A team that's honest about "we're at 14, the leader in our category is at 22" knows exactly what to ship next quarter. A team without the audit just feels vaguely behind.
The fastest items first
If you've got an afternoon and need the highest leverage per hour invested, do these five in this order:
- Ship a clean
/llms.txt— under 5 minutes with our llms-txt generator, and it gives every AI crawler a curated entry point. Highest-ROI single item on the list. - Audit your robots.txt for AI crawler blocks — 10 minutes with our robots.txt checker. If GPTBot or ClaudeBot is silently blocked, nothing else you do matters.
- Build complete Organization JSON-LD — 20 minutes with our schema generator. Include the full
sameAsarray. Six months of citation lift for a one-time ship. - Add FAQPage schema to your top 5 pages — another 15 minutes per page with the schema generator. Perplexity citations lift within two weeks.
- Claim your Wikidata QID — 20-30 minutes at wikidata.org if your entity already exists; an hour if you're creating it. Free, permanent, and links your brand into the entity graph every foundation model is pre-trained on.
Two hours of focused work, and you've moved roughly 5 to 7 checklist items. The remaining 23 take longer per item but compound.
How to run this audit automatically
Or skip the manual work. Our AEO audit tool runs the 30 checks above plus 20 more in 30 seconds — schema validation, llms.txt parsing, robots.txt crawl-permission graph, Wikidata lookup, third-party review scraping, per-engine citation testing, and a ranked fix list. Free, no signup, no card on file. One scan per day per IP on the free tier, powered by Google Gemini; paid tiers unlock weekly tracking and the full multi-engine sweep across all nine AI assistants. The rest of our AEO tools catalog covers the individual pieces — schema generation, llms.txt, citation source radar, prompt generation — that you'll want once you have a measurement baseline. You can also query the same scores straight from Claude or ChatGPT through the FixAEO MCP server.
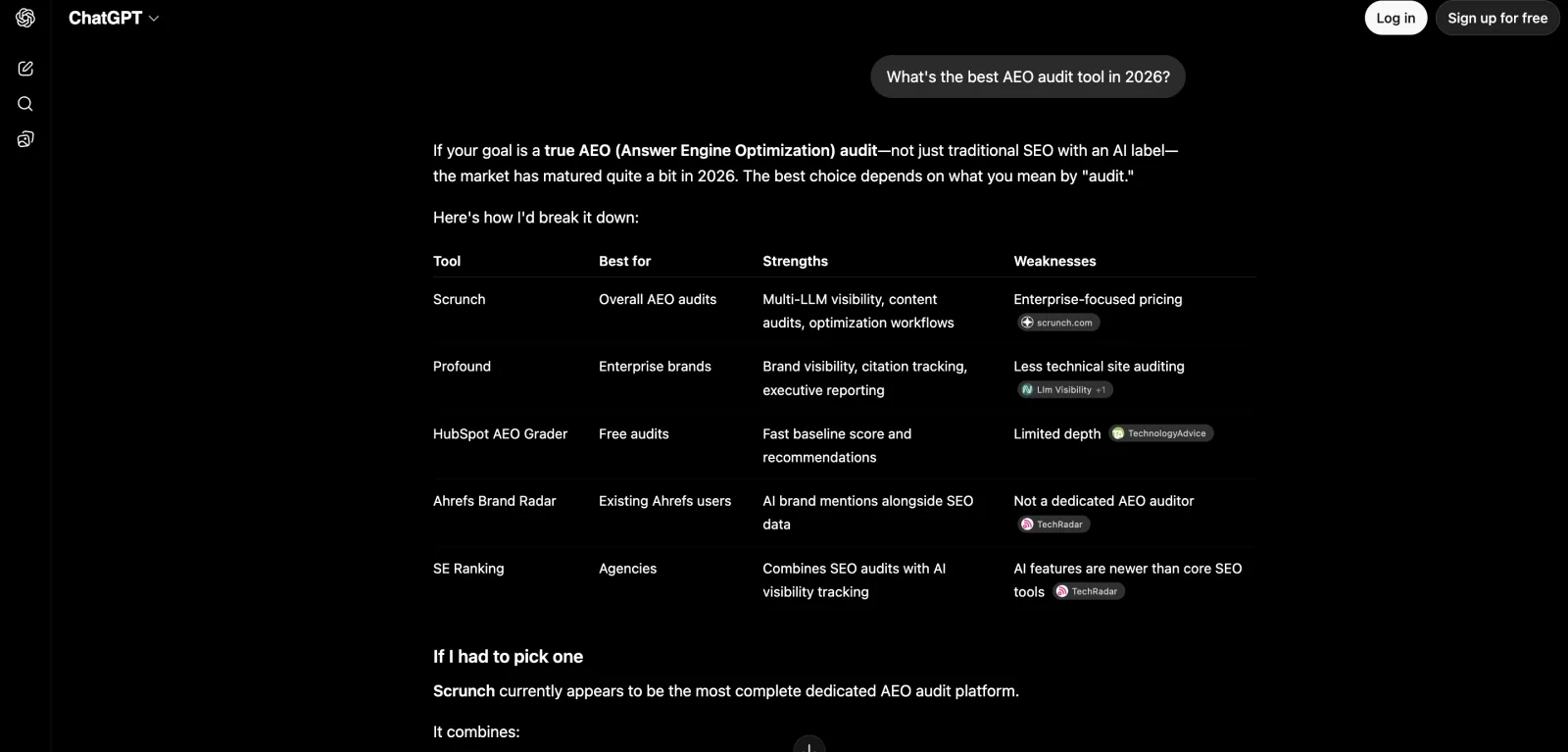
Example: ChatGPT (logged out) answering 'best AEO audit tool in 2026' — Scrunch, Profound, HubSpot, Ahrefs, SE Ranking. These are the tools buyers get pointed to.
For a curated comparison of FixAEO against the rest of the AEO tool market, see our honest writeup of the best AEO tools in 2026.
TL;DR
Answer Engine Optimization has 30 distinct signals across 7 categories: crawler access, structured data, content structure, entity signals, third-party signals, per-engine checks, and measurement. Most teams check 8 to 12 on a first pass. A focused quarter gets to 20 to 25. All 30 is rare. The fastest wins are crawler access (llms.txt, robots.txt) plus structured data (Organization + FAQPage schema) plus question-form H1s on your top pages. Use this checklist as the AEO audit template for your team, or run the same 30 checks automatically with our AEO audit tool and let the AI visibility checker measure weekly whether your work is moving the citation number.
FAQ
How many signals are in the AEO audit checklist?
The checklist covers 30 distinct signals across 7 categories: crawler access, structured data, content structure, entity signals, third-party signals, per-engine checks, and measurement.
How long does an AEO audit take to run?
A thorough first-pass audit runs 3 to 5 hours end to end, with each item taking 5 to 30 minutes the first time. Re-run it quarterly, since AI engines change fast and third-party signals decay.
How many of the 30 AEO checklist items do most teams pass?
Most teams running this audit for the first time check 8 to 12 of the 30 items. After a focused quarter, that rises to 20 to 25, while checking all 30 is rare and sits in competitive-moat territory.
What are the fastest AEO audit wins?
The highest-leverage items are crawler access (ship a clean llms.txt, audit robots.txt for AI crawler blocks) plus structured data (complete Organization JSON-LD and FAQPage schema on top pages) and question-form H1s on your top pages. Two hours of focused work moves roughly 5 to 7 checklist items.
Can I run the AEO audit automatically instead of by hand?
Yes. The FixAEO AEO audit tool runs the 30 checks above plus 20 more in about 30 seconds — schema validation, llms.txt parsing, robots.txt crawl-permission graph, Wikidata lookup, third-party review scraping, and per-engine citation testing — and the checklist works either way if you prefer to audit by hand.
Footnotes
-
Anthropic — Does Anthropic crawl data from the web, and how can site owners block the crawler? Read Anthropic's crawler docs. ↩
-
llmstxt.org — The /llms.txt file. Read the spec. ↩
-
Schema.org — Article. Read the type definition. ↩
-
Wikipedia — Notability (organizations and companies). Read the notability guideline. ↩
Related reading
AEO vs SEO: what changed and what to do about it
AEO vs SEO in 2026: AI answers and search engines reward different signals. The data, a plain comparison, and a 30-day migration plan your SEO team can run.
17 min readWhat is AEO? Answer Engine Optimization explained
Answer Engine Optimization (AEO) means getting AI assistants to recommend your brand. Learn what AEO is, why it matters more than SEO, and how to start.
17 min read12 Best Answer Engine Optimization Tools (2026)
12 answer engine optimization tools compared — engines covered, entry price, free tier — with honest takes on which to pick by stage and budget.
18 min readHow to measure AEO ROI: a copy-paste spreadsheet
AEO doesn't generate clicks the way Google does. Here's a concrete 4-metric framework + the spreadsheet to track ROI on every AEO investment.
13 min readHow to add llms.txt to your website in 10 minutes
llms.txt tells AI assistants what your site is about. Get the exact format, a copy-paste template, and deployment steps for every major host.
7 min readAEO for SaaS: Get Recommended by AI Assistants
AEO for SaaS companies: why G2 reviews outweigh content, how comparison pages win, and the playbook to get your product into AI answers.
13 min read
Free AEO tools
Put this into practice with free FixAEO tools — no signup required.
AI Visibility Checker
Score your brand across 9 AI engines
AEO Audit Tool
Answer-engine readiness scan
Schema Generator
Build valid JSON-LD structured data
llms.txt Generator
Create a spec-compliant llms.txt
Sitemap Validator
Check your XML sitemap for errors
AI Content Grader
Grade content for AI citation readiness
See how your own site scores
FixAEO runs every check in this post automatically. Free, no signup.